How Do We Judge AI Vulnerabilities?
As developers deploy AI systems, vulnerabilities are being surfaced by a range of actors and methods — from safety institutes to public bug bounty programs. While it is important to disclose these vulnerabilities quickly, the safety community currently lacks a shared framework for rating vulnerability risks in order to prioritize remediation for model developers. In the cybersecurity world, it is common practice to rate Common Vulnerabilities and Exposures (CVEs) as they are publicly disclosed, giving security teams a reference point upon which they can build governance processes for their own systems.
While a handful of frameworks for addressing model vulnerabilities have been introduced, the growing number of vulnerability disclosures makes it increasingly important to clearly articulate and prioritize the risks associated with disclosed findings. This paper builds on AISI’s ongoing evaluation work on model safeguards, and research on safety cases to investigate how we might move towards severity judgement frameworks for AI vulnerabilities.
Scoring Vulnerabilities: Taking cues from cybersecurity
As we move towards a standardized severity framework for AI vulnerabilities, we might look towards cybersecurity rating practices as a starting point. As noted, CVEs are disclosed with an associated rating, and these ratings are generally calculated using the Common Vulnerability Scoring System (CVSS). This framework takes into account a range of characteristics to render a rating out of ten. Scoring includes elements like exploitability (remote vs. local), system impact (data disclosure vs. loss), and automatability (can the exploit be scripted?).
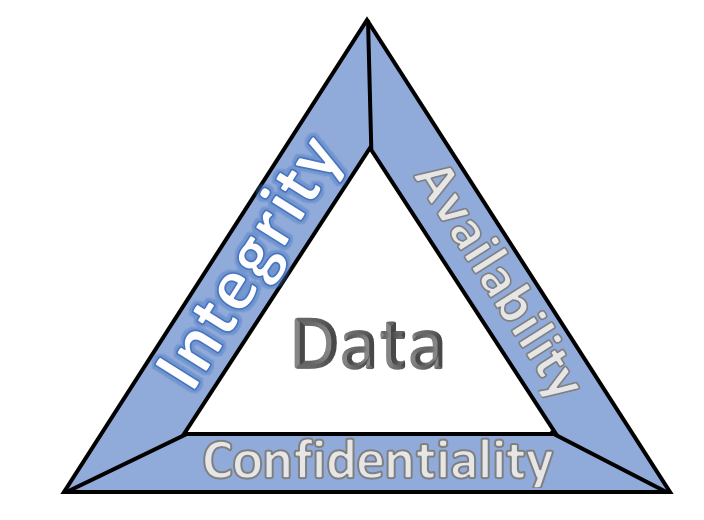
These characteristics are historically grounded in the CIA triad—confidentiality, integrity, and availability — which foregrounds attacker goals like extraction, manipulation, or destruction of sensitive data. Broadly, the goal of CVSS scores is to place a vulnerability in context. For AI evaluation, choosing which characteristics should be included within a CVSS-style scoring system is an important challenge.

Taxonomies: How do we differentiate vulnerabilities in AI models?
Even this year, OWASP proposed their combination of CVSS and AI risk with the AVISS - a framework which scored vulnerabilities based on risks like agent autonomy, tool access and context injection. Drawing on CVSS might be a good place to start, but cybersecurity has more robust risk management infrastructures than AI risk, including well-defined taxonomies of attack types and risks. Thinking more about taxonomies of AI attacks and risks is a crucial step towards risk scoring.
The US National Institute of Standards and Technology (NIST) offered a few approaches to define adversarial machine learning techniques in March 2025. Their overarching taxonomy focused on attacker goals, building on the CIA triad, this time introducing misuse as a novel goal for attackers targeting generative AI models. Taking their updated CIA-M tetrad as a foundation, the report also differentiated attacks based on technique and attacker access in an effort to contextualize methods and goals together.
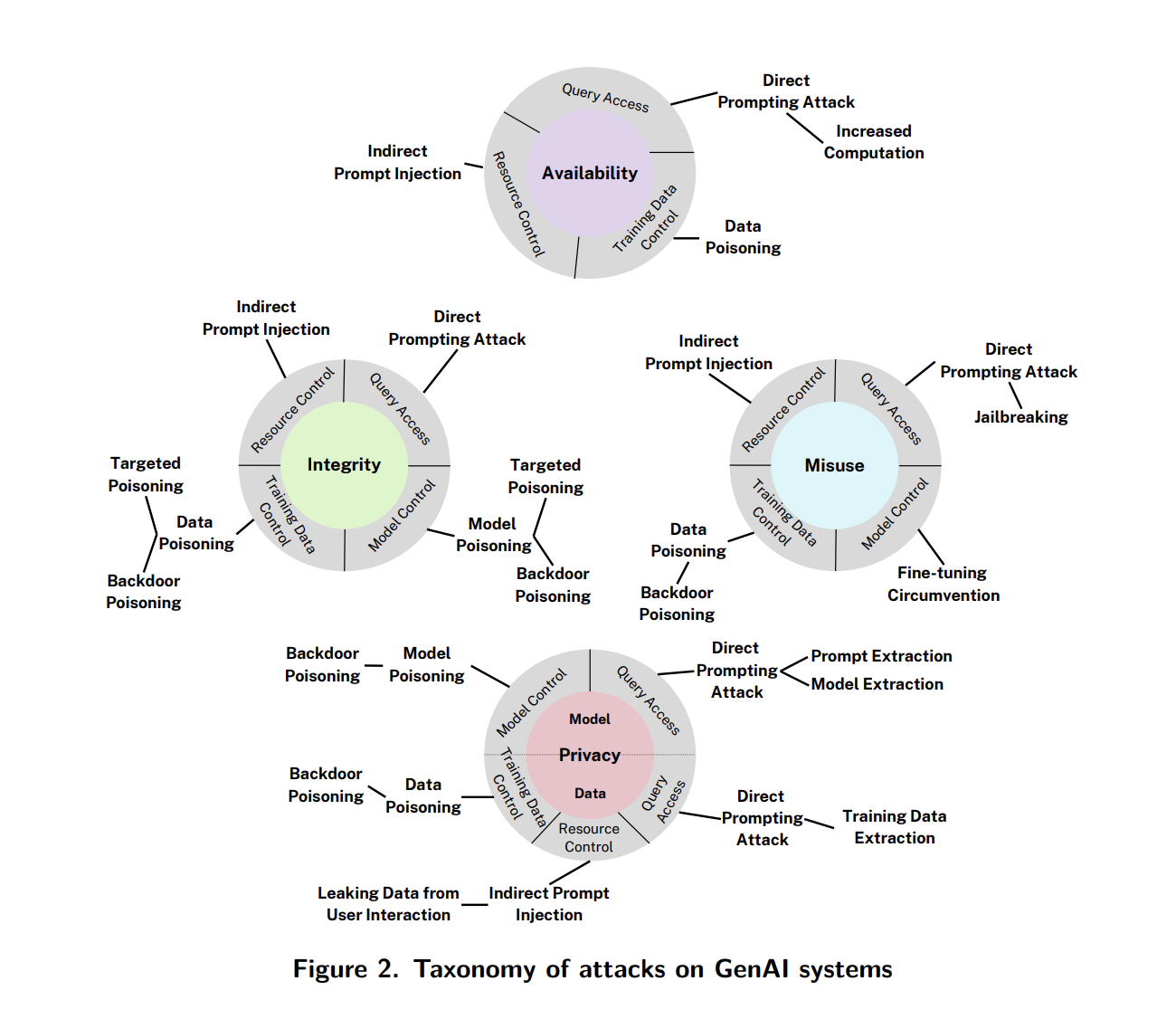
{kind=link}
Alternatively MITRE offered its own adversarial AI taxonomy, ATLAS, adapted from its well-established cyber framework ATT&CK. Like ATT&CK, ATLAS focuses on an attacker’s stage in an adversarial lifecycle, highlighting categories like reconnaissance, initial access, and data exfiltration. These lifecycle-based categories help defenders trace where vulnerabilities fit into an attacker’s campaign, as opposed to a goal-oriented approach.
Taken together, these organizations highlight the tension between different approaches to outlining risks — attacker goals, attack technique, system capability, and potential harms all can play a role in assessing risks posed by a vulnerability. A robust rating system for AI safeguard vulnerabilities will need to translate well across these perspectives.
Examining Challenges With a Case Study
In a recent paper, researchers bypassed model safeguards by using fine-tuning APIs to train their customized model to have weakened safeguard protections. Even more interesting, they were able to use benign-seeming question/response pairs for fine-tuning, making detection more difficult. This attack clearly poses a significant risk, but defining that risk is not straightforward, even using the taxonomies above.
Both the NIST and MITRE taxonomies would be useful in categorizing some aspects of this attack — using NIST we may categorize this as model-poisoning for the purposes of misuse; with MITRE we might categorize it as an effort to maintain adversarial “persistence” using a manipulation technique. In other words, if we have default ratings for model-poisoning or persistence, then we have some basis for assigning a rating and priority.
In the case of misuse, though, risk largely depends on the underlying model’s capability. If the vulnerable model itself is not very good at cyber-related tasks, it is unlikely that bypassing safeguards would give an attacker access to a model that poses significant harm. Future research is needed to connect the large ecosystem of benchmarks used to evaluate AI systems to more concrete risk ratings in these kinds of cases.
Another consideration is how we may deal with making severity judgments on an emerging technology. For instance, the taxonomies discussed above do not differentiate between open-weight and proprietary models, even though open-weight models are not particularly novel. In this example, the vulnerability involves bypassing API fine-tuning safeguards on a proprietary model. But the same underlying weakness (using fine-tuning to degrade safeguards) also exists in open-weight models. While this distinction might seem minor, it becomes important when designing mitigation strategies, and could impact risk rating if we consider remediation effort. It is easy to imagine that complexity will continue to ramp up, and consequential missing taxonomies will increase as we continue to judge the severity of findings. This example highlights both how taxonomies in a fast-moving field are inherently provisional, and that increasing complexity will make static classifications difficult to maintain — a challenge also noted by NIST elsewhere.
Conclusion
Establishing a standardized framework for rating AI vulnerabilities will require reconciling competing taxonomies, adapting cybersecurity practices, and accounting for unique features of AI systems. Without such a framework, disclosures might fragment and undercut coordinated mitigation, leaving developers and regulators without a shared basis to prioritize real security threats.